这两天的朋友圈,被OpenAI的一款王炸级文生视频大模型—「Sora」刷屏了。只要输入基础的文本指令,便可生成一段长达60秒的高清视频。一位时尚的女人走在东京的街道上,街道上到处都是温暖的发光霓虹灯和动画城市标志。她身穿黑色皮夹克,红色长裙,黑色靴子,背着一个黑色钱包。她戴着墨镜,涂着红色口红。她自信而随意地走路。街道潮湿而反光,营造出五颜六色的灯光的镜面效果。许多行人四处走动。 2月16日凌晨,头部人工智能公司OpenAI 突然发布了自己的首个文生视频模型:Sora。OpenAI表示Sora能够生成复杂的场景,不仅包括多个角色,还有特定的动作类型,以及对视频内容的准确细节描绘。就单单拿上面的视频举例,OpenAI所言非虚:60秒的一镜到底,多镜头所以切换,视频中的女主角、乃至其背景人物,都非常稳定和清晰。Sora的神级技术效果不仅大幅刷新行业多个指标,更是给了Runway Gen 2、Pika、Stable Video这些跃跃欲试的AGI视频同行当头一棒。在它们还探索着几秒内的视频连贯性时,Sora却能实现长达1分钟的复杂视频,几乎以一已之力颠覆了生成式AI在视频领域的全球市场格局。3个“革命性”进步 概括来说,Sora体现的「颠覆性」主要体现在下面三个方面:要知道,在Sora之前,受制于时空推理局限性,行业的普遍水平是2-4秒之间,很多人打趣地说道“与其说是视频,不如说是动图”。而此次Sora的最大支持长度是60秒,直接飙升15倍。此前AI生成视频产品基本都是单镜头生成,主要展现的是让一张静态图片动起来。但由Sora所生成的视频,能够在保持主体一致性的前提下实现多角度镜头无缝切换,且能做到画面稳定、场景一致,还兼具着高保真度和高分辨率。其他家AI文生视频同行所运用的基础模型架构更像是“小”模型的思路——基于上一帧预测下一帧,并且用文字或者笔刷遮罩做约束。但Sora则已经具有了世界模型的雏形———准备足够大量的视频,用多模态模型给视频做标注,把不同格式的视频编码成统一的视觉块嵌入,然后用足够大的网络架构+足够大的训练批次(batch size)+ 足够强的算力,让模型对足够多的训练集做全局拟合(理解)。所以其生成的视频是基于对真实物理世界的理解。这些demo中,Sora不仅能准确呈现细节,还能理解物体在物理世界中的存在,并生成具有丰富情感的角色。值友们一起来看看:一窝金毛幼犬在雪地里玩耍。他们的头从雪中探出来,被雪覆盖着。 动画场景的特写是一个毛茸茸的小怪物跪在融化的红蜡烛旁边。艺术风格是 3D 和现实的,重点是灯光和纹理。这幅画的气氛是一种惊奇和好奇,怪物睁大眼睛、张开嘴巴凝视着火焰。它的姿势和表情传达出一种天真和俏皮的感觉,就好像它第一次探索周围的世界一样。暖色调和戏剧性灯光的使用进一步增强了图像的舒适氛围。 一位 24 岁女性眨眼的极端特写,在魔法时刻站在马拉喀什,70 毫米拍摄的电影胶片,景深,色彩鲜艳,电影般。 另外,OpenAI首席执行官奥特曼也在X网站上发起征集,让用户把自己想给Sora的文字描述提交给他来生成视频:“不用担心你的要求太细,或是难度太大!”有人提出想要“一段海上自行车比赛的视频,让各种动物作为运动员骑自行车,采用无人机拍摄视角”。奥特曼在回复中发布了一段由Sora生成的视频,视频中有企鹅、海豚和其他水生生物骑自行车,可谓天马行空。如果这样还不能让你有直观感受的话,可以看看Sora与其他AGI视频工具的对比效果。雪后的东京熙熙攘攘。镜头穿过繁忙的街道,跟随着几位享受着美丽雪景和在附近摊位购物的人们。美丽的樱花瓣伴随着雪花在风中飘舞。 为了验证SORA的效果,业界KOL Gabor Cselle把它和Pika、RunwayML和Stable Video进行了对比。
首先,他采用了与OpenAI示例中相同的Prompt。结果显示,其他主流工具生成的视频都大约只有5秒钟,而SORA可以在一段长达17秒视频场景中,保持动作和画面一致性。随后,他将SORA的起始画面用作参照,努力通过调整命令提示和控制相机动作,尝试使其他模型产出与SORA类似的效果。
但又一轮对比之下,似乎SORA还是更加优秀——无论是长镜头还是对文字的理解能力。Sora已经完美了吗? 没有。尽管Sora已经把同行甩开身位,但也远没有达到成熟水准。OpenAI在官网上就主动指出来它可能难以准确模拟复杂场景的物理原理,并且可能无法理解因果关系的具体实例。它虽然能模拟一些基础物理互动,比如玻璃的碎裂,但还不够精确。再比如混淆方向感,下面这个人正在跑步机上反向跑步,动作也不是很自然:还有不准确的物理建模和不自然的物体“变形”的例子。下面这个篮球撞在篮筐上,发生了爆炸。再比如“五只灰狼幼崽在一条偏僻的碎石路上互相嬉戏、追逐”,一开始是三只狼,又凭空出现或消失了第四、第五匹狼。当然,Sora毕竟还只是最初测试版本,按照Open AI目前的训练情况和模型迭代速度,更多的人愿意相信这些弱点会很快被攻克。
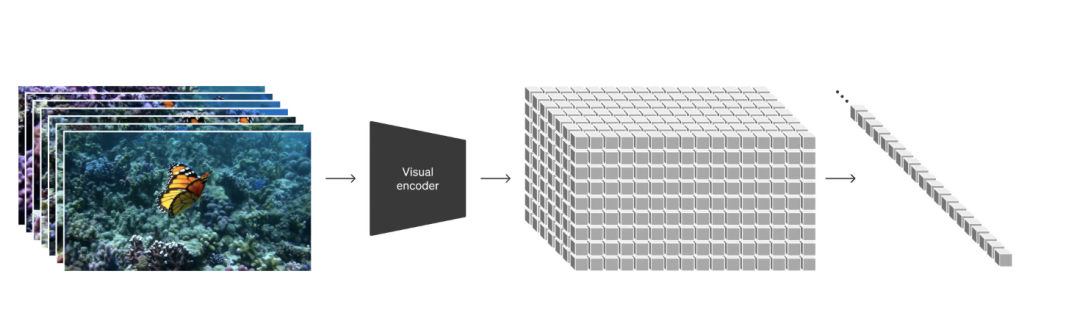
与此同时,Sora的技术报告也公布在官网。Open AI表示,Sora是能够理解和模拟现实世界的模型的基础,他们相信这一功能将成为实现 AGI 的重要里程碑。此前,OpenAI的研究者一直在探索的一个难题就是:究竟怎样在视频数据上,应用大规模训练的生成模型?更进一步说,怎么能实现「逼真」二字?要知道,传统检索是按图索骥,从数据库固定位置调取信息,准确度高,但不具备举一反三的能力。而生成式AI模型不会去记住数据本身,而是从大量数据中去学习和掌握生成语言、图像或视频的某种方法,产生难以解释的“涌现”能力。为此,研究者同时对对持续时间、分辨率和宽高比各不相同的视频和图片进行了训练,而这一过程正是基于文本条件的扩散模型。Open AI也强调,Sora是一种扩散模型,它从看起来像静态噪声的视频开始生成视频,然后通过多个步骤消除噪声来逐渐对其进行转换。以前的许多研究,都是通过各种技术对视频数据进行生成模型建模,比如循环网络、生成对抗网络、自回归Transformer和扩散模型等方法。它们往往只关注于特定类型的视觉数据、较短的视频或者固定尺寸的视频。而Sora与它们不同,他们将视频和图像表示为称为补丁的较小数据单元的集合,每个补丁类似于 GPT 中的令牌。通过统一表示数据的方式,可以在比以前更广泛的视觉数据上训练扩散变换器,涵盖不同的持续时间、分辨率和纵横比。Sora 建立在过去对 DALL·E 和 GPT 模型的研究之上。它使用 DALL·E 3 的重述技术,该技术涉及为视觉训练数据生成高度描述性的标题。因此,该模型能够更忠实地遵循生成视频中用户的文本指令。除了能够仅根据文本指令生成视频之外,该模型还能够获取现有的静态图像并从中生成视频,准确地动画图像的内容并关注小细节。
Sora来了,有些人真要失业了? Sora发布之后,不仅在网上收获了满堂彩,也让很多人惊呼很多行业恐将重新洗牌。毕竟“工欲善其事,必先利其器”,现在的“器”——文案、图片、视频、音效等一系类AI工具可以说万事俱备了,只欠“好内容”、“好文本”、“好故事”。人类独有的想象力和创意表达,甚至是能够清晰描述需求的能力提升到了无比重要的高度。无论是ChatGPT还是Sora ,无论是创作一段60秒视频还是写一个故事文案,关键都在于你能否提供有效的问题、以及清晰的描述Prompt。所以类推到影视行业,Sora带给它们的冲击无疑是最大的。演员、摄影师、剪辑师、特效师不免担心其被替代风险,编剧反而被提高到无与伦比的地方,其剧本和内容创作成了核心竞争力。事实上,影业公司使用AI制作图片和视频,并不是什么新鲜事。《瞬息全宇宙》使用了Runway的AI视频工具;去年21世纪福克斯已经与IBM沃森合作,用AI工具为关于AI主题的恐怖片《摩根》制作预告片;迪士尼旗下的漫威更完全用AI制作了《秘密入侵》的开头动画。落到短视频平台,短视频推荐的形态可能会发生改变,用户创作可能也会迎来指数级增长,新的流行似乎不可阻挡。评论区大家都很兴奋,似乎对实现“导演梦”充满期待——迫不及待地希望把自己喜欢的网文/动漫(甚至是一些大尺度的)生产成影视作品。不过大家也别急着天马行空,OpenAI 内部仍在进行模型伦理侧的对抗性测试,比如错误信息、仇恨内容、偏见内容,至于色情暴力,则会在文本输入时,就被拒绝掉。
除了AIGC产业充满了无限可能外,其他行业也充满着机会。比如以苹果vision pro为代表的XR产业,常常被诟病内容匮乏、生态建设不足,有了Sora加持,或许能再次获得助力。Sora的世界模型自然需要足够强的算力,那么对于英伟达这样的一众显卡公司显然也是利好。谈及Sora发布后的影响,一些圈内大佬也陆续发表了他们的观点。
马斯克感叹“人类愿赌服输”,360创始人周鸿祎认为“Sora可能给广告业、电影预告片、短视频行业带来巨大颠覆,成为激发创作力的工具”,并预言“AGI实现将从10年缩短到1年”。美国旧金山早期投资人Zak Kukoff预测一个不到5人的团队将在5年内用文生视频模型和非工会的劳动力制作一部票房收入超过5000万美元的电影。此外,前阿里技术副总裁、目前正在从事AI架构创业的贾扬清也针对Sora在朋友圈发布了他最新的观点:“1、对标OpenAI的公司有一波被其他大厂fomo收购的机会。2、长线闭源寡头,开源还需要一段时间才能追赶上。3.、从算法小厂的角度,要不就算法上媲美OpenAI,要不就垂直领域深耕应用,要不就选择开源。4、基础设施的需求继续会猛增。”此前OpenAI花了大约半年来测试其大语言模型GPT-4。如果测试Sora需要差不多的时长,这个强大的视频生成工具可能会在8月份开放。不过考虑到深伪技术带给美国大选的负面影响,OpenAI估计会谨慎考虑正式公开Sora的时间。无论如何,Sora展现的“革命性”无疑给大部分行业提供了降本增效的可能性,更是给远离视频行业的普罗大众打开了一扇创造虚拟世界的大门。 |







 发表于 2024-2-18 15:58:01
发表于 2024-2-18 15:58:01